How to setup Hermes with Ollama is the question, but the better question is why you'd run Hermes locally at all rather than just paying for cloud APIs.
I started on cloud APIs and hit £200+ in monthly bills before I knew what was happening. Then I switched most of my agents to local Ollama and the bills dropped to almost nothing.
This post is the honest breakdown — why I made the move, what I gained, what I lost, and how you set it up if you decide to switch too.
The Real Reasons Cloud Got Expensive
I wasn't doing crazy work — just running an SEO content agent and a research agent with a few hundred queries a day.
The bills crept up because long context windows burn tokens fast, web scraping returns enormous text blocks, and multi-step tool calls fire multiple completions per task. By month three I was paying for a meal out every day in API costs.
Local fixes that.
What Local Ollama Models Actually Cost
Pence per day on electricity. That's it.
You buy your hardware once. The models are free. The runtime is free. Compared to cloud, you save 95%+ on actual compute costs.
What I Lost When I Switched
I'll be honest about the tradeoffs. Local models aren't quite as smart as the top-tier cloud models in a few specific ways. Edge-case reasoning is weaker, very long context above 100K tokens is harder, and some niche skills work better with cloud quality.
For 80% of daily tasks you won't notice the difference.
For the remaining 20%, I keep one cloud provider in Hermes as a backup and switch to it when I really need the firepower.
My Hybrid Setup (And Why It Works)
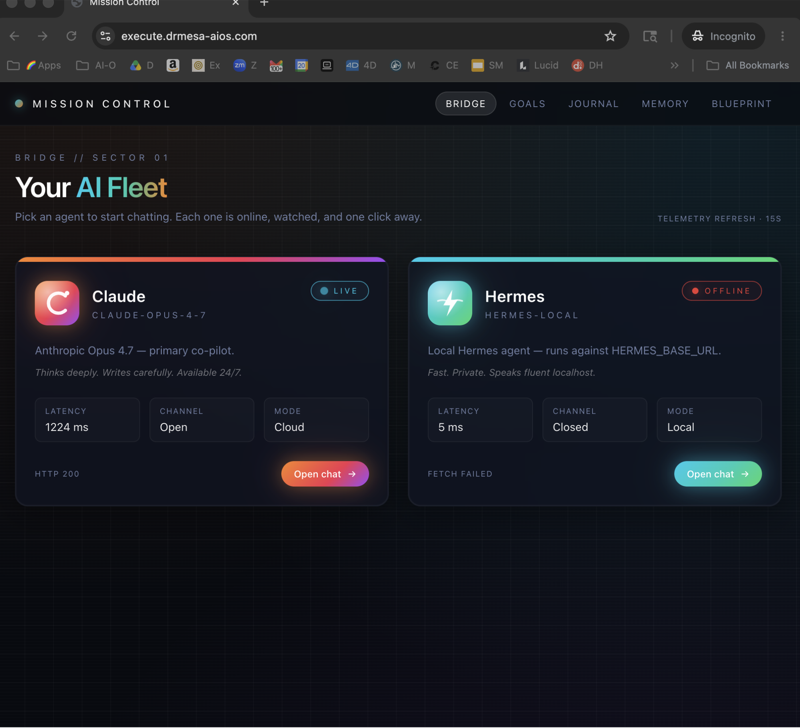
I run Hermes pointed at three providers. Ollama running locally handles the daily work. DeepSeek's cloud free tier handles the few tasks that need cloud quality. OpenRouter handles one-off experiments with new models.
Hermes lets me switch between them per agent or per chat, which gives me the best of both worlds without locking in.
If you want the same hybrid play, my Hermes DeepSeek setup covers how I configure cloud as the second option.
🔥 Want my full hybrid Hermes setup? Inside the AI Profit Boardroom, I share the exact hybrid config — local + cloud providers, agent assignments, model switching rules, and a 2-hour Hermes course covering every workflow. Plus weekly live coaching where you can ask anything live. 3,000+ members building real automations. → Get the setup here
How To Setup Hermes With Ollama
Here's the actual setup, step by step.
1 — Get Ollama installed
Head to ollama.com and download the installer for Mac, Windows, or Linux. Ollama runs as a local server in the background once installed, so there's no daemon to manage.
2 — Pull a model
Open terminal and run a model command like ollama run gemma4 or ollama run deepseek, then wait for the download to finish.
3 — Get Hermes installed
If you don't have Hermes yet, install it from its GitHub repo. The non-technical shortcut is to copy the install command into Claude Code or Codex and ask it to run the install for you.
4 — Point Hermes at Ollama
In your Hermes config, set the provider to ollama, the URL to http://localhost:11434, and the model to whichever one you pulled in step 2. Restart Hermes after saving.
5 — Test it
Send a message to your agent. If you get a reply, the setup is working and you're done.
How To Setup Hermes With Ollama — Picking The Right Model
Don't overthink this. Gemma 4 at roughly 7GB is the best lightweight default. DeepSeek is the best agentic default because it's designed for agent tasks. Nemotron 3 Nano Omni from Nvidia is the best for sub-agent setups. Qwen 3.6 is the best general-purpose option.
For most people, start with DeepSeek. If your machine can't handle it, drop to Gemma 4.
What Daily Hermes Use Looks Like For Me
A normal day looks like this. At 8am Hermes pulls overnight news via web search. At 9am it drafts content briefs based on the news. At 10am it sends them to my Notion. At midday it handles email triage. In the afternoon it runs background tasks like SEO research, draft tweets, and calendar prep.
All of that runs on Ollama models locally. The total bill is zero.
What I Wish I'd Known Sooner
A few lessons I learned the hard way.
Local models scale with your hardware, so a bigger machine means better local performance. If you're on a laptop, expect smaller, faster models rather than the biggest one.
Always keep Ollama running. Hermes loses access if Ollama isn't on. I've got Ollama set to auto-start at login so I never have to think about it.
Don't fight cloud entirely. Keep one cloud provider as backup because there are tasks where cloud is genuinely better.
Models I'd Avoid Locally
Three traps to watch out for.
Don't run massive parameter models on small machines. A 70B parameter model on a 16GB MacBook will choke and you'll hate the experience.
Avoid older models that haven't been agent-tuned. Stick to the agent-friendly picks above for anything that involves tool use.
Avoid anything not on Ollama's official list. Third-party model wrappers can be flaky, so stick to first-party releases.
Speed Reality Check
Local is slower than cloud for first-token latency. Cloud might give you a response in 1.5 seconds. Local might take 4-6 seconds on similar prompts.
For chat that's noticeable. For automation that runs in the background, it doesn't matter at all.
When Cloud Still Wins
Be honest with yourself about when to use cloud. Real-time chat with users where latency matters. Very long context above 100K tokens. Tasks that need top-tier reasoning capability.
For everything else, local Ollama is fine.
Why Hermes Pairs So Well With Ollama
Two reasons make this combination work.
Hermes was designed to support multiple providers from day one, so switching between Ollama and cloud is a config change rather than a rebuild.
Hermes' skills work the same on local or cloud. You don't lose web search, browser, terminal, or memory profiles when you go local. That makes the migration painless.
🚀 Want my full local + cloud Hermes setup? The AI Profit Boardroom has my exact provider config, model switching rules, and a 2-hour Hermes course. Plus a 6-hour OpenClaw course covering both agents side by side. Daily training drops and 3,000+ members. → Join here
FAQ — How To Setup Hermes With Ollama
Why use Ollama with Hermes instead of cloud?
Cost — local models cost pennies per day in electricity versus hundreds per month on cloud APIs.
Is Hermes free with Ollama?
Yes — both Hermes and Ollama are free, and local models cost nothing per token.
How long does the setup take?
10-20 minutes including the model download.
Is local quality good enough?
For most tasks, yes. For top-tier reasoning, cloud still has an edge.
Can I use both local and cloud in Hermes?
Yes — Hermes supports multiple providers and you can switch per agent or per chat.
Best Ollama model for Hermes?
DeepSeek for agent tasks, Gemma 4 for low-spec machines, and Nemotron 3 Nano Omni for sub-agent setups.
Do I need a special GPU?
No — Ollama uses what you have. A modern laptop CPU runs small models fine. A GPU helps with larger models.
Related Reading
- Hermes Gemma 4 — beginner-friendly local setup.
- Hermes DeepSeek — best agentic model for Hermes.
- Ollama Hermes — deeper Ollama walkthrough.
📺 Video notes + links to the tools 👉
🎥 Learn how I make these videos 👉
🆓 Get a FREE AI Course + Community + 1,000 AI Agents 👉
If your API bills are climbing, this is exactly how to setup Hermes with Ollama and switch to a free local AI agent stack.